

Synthetic biology researches are based on standardized biological parts, and the scientists should explore various metabolism databases to design their own devices or circuits. However, it is hard for researchers to design a proper biochemical pathway due to a considerable amount of data available on the Internet. Korea U Seoul, therefore, developed a web application ‘Gil’, which means “path” or “road” in Korean. This software is a spin-off version of ‘IPNN’. A researcher can search which set of reactions or genes is required to conduct a successful experiment.
The software ‘Gil’ is a bio-pathfinder for synthetic biologists. Given only a reactant and a final product, a user can obtain possible paths using our program. For instance, if you want to break some agarose into pyruvate, the ‘Gil' will show you maximum 12 optimal paths composed of biologically proven reactions. In addition, the biological scoring system is another significant feather of this software. The ‘Gil’ is able to calculate the increase and decrease of the number of ATP, NADH, NADPH, and CO2, and provide the maximum three output paths, respectively. Also, the ‘Gil’ contains BioBrick part registry, E. Coli K-12 gene data, and the Gibbs free energy of each reaction. This information helps people find the most plausible de novo pathway just like Google Maps.

The program ‘Gil’ is a project based on KEGG (Kyoto Encyclopedia of Genes and Genomes) database (KanehisaM., et al. 2014; and KanehisaM., GotoS., 2000). There are numerous advantages of KEGG. Above all, KEGG has a nice interface. In an overview graphic, we can take all reactions of a pathway, and see the enzymes that are involved in the reaction by clicking individual reactions. In addition, there are most information about the gene linked with this enzyme. So we organized and parsed the databases that provide information of compounds, reactions, genes and enzymes.
However, KEGG database is definitely not perfect. First, it doesn't provide thermodynamic data. Additionally, KEGG database shows reactions in a bidirectional way, which lacks the information of thermodynamical feasibility. Also, KEGG is a pure gene database. While each enzyme has a large amount of gene information attached, it lacks a bit in the other departments. Therefore, users easily encounter empty pages that do not have any information. Lastly, every glycan in KEGG database is not connected with its corresponding compound. When glycan IDs are not connected to compound IDs, it is not possible to find a reaction with a glycan.
Thermodynamic constraint is one of the most important factors of biological experiments. Therefore, the program ‘Gil’ provides Gibbs energy changes of each metabolic reaction.
The program ‘Gil’ obtained thermodynamic data from two separated databases even though they were obtained from the same program, eQuilibrator (Flamholz A., et al. 2012). The first database is composed of Gibbs free energy from standard condition—pH 7.0 and 0.1 M ionic strength. These data are correct, but the size of the database is smaller than the other one due to the lack of wet lab experiments. On the other hand, the second version is made up of values from a calculation. This database has much more values than the first one however, it is hard for researchers to apply this values directly to their experiments since they are not experimentally proved. Thus, additional attention is needed to utilize the second version of data.
We calculated scores of every output path and picked up the three optimal paths from each scoring factors. When it comes to a set of compounds, the maximum twelve paths are formed into a network, scores, BioBrick interlinking information, and other related data. We saved that information into JSON and text format. When it comes to the standard biological parts, there are 24,133 parts IDs and sequences. We filtered the sequences shorter than 100 bp, and 19,808 parts were left. As a result, after running the Nucleotide BLAST to KEGG GENES data, 565,163 matches were found (with E-value of 1e-5). The number of 3972 parts were linked to 20,276 gene IDs.

Most chemical compounds with carbon produce a product through a synthetic-dissociation pathway. The decarboxylation, the dissociation of carbon, will lose carbon equivalent and limit the product’s theoretical carbon yield. The Formula 1 show you how to calculate the efficiency of a pathway.
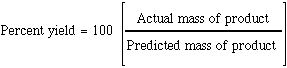
We assume that non-oxidative glycolysis (NOG) as a model mechanism to develop our software program. NOG is one of the complete carbon yield pathways that starts with sugar to acetyl-CoA. It needs conjunction with carbon dioxide or assimilation with other one-carbon (C1) source to produce desirable fuels and chemicals (Bogorad I. W., Lin T. S., Liao J. C. 2013).
While simulating the NOG pathway, we achieved complete carbon yield. So without losing any of carbons, we are able to obtain desirable results. During the reaction, there are lots of chemicals that result in carbon loss. The program ‘Gil’ calculates the CO2 reduction to calculate the carbon loss. This is due to the fact that CO2 is less likely to be utilized unless it is fixed compared to other chemicals
Another scoring factor which the program ‘Gil’ provides is the ATP quantity. This function is expected to be useful for synthetic biologists to design reaction pathway necessary for their experiments which are designed to have higher efficiency when there is increased ATP level.
Substituting the biological reaction with the ones that have higher ATP yield, designed by the program ‘Gil’, will possibly increase the productivity of both organisms. The following KEGG compound number order is the examples of the reaction pathway: C00031 (glucose), C00394, C00035, C00144, C00044, C04895, C00084, C00469 (ethanol).
Like an ATP (adenosine triphosphate) which serves as a convenient and versatile storage in cells, NADH (nicotinamide adenine dinucleotide) and NADPH (nicotinamide adenine dinucleotide phosphate) serve as activated carriers specialized in carrying high-energy electrons and hydrogen atoms.
The two types of carriers are used to transfer electrons (or hydride ions) between different sets of molecules. This role separation is crucial for organisms to regulate two sets of electron-transfer reactions independently. An NADPH operates mainly with enzymes that catalyze anabolic reactions, providing the high-energy electrons needed to synthesize energy-rich biological molecules. In contrast, an NADH has a special role as an intermediate in the catabolic system of reactions that generate ATP through the oxidation of compounds (Alberts B., et al. 2002).
Then, why should we focus on the larger amount of NADH and NADPH as products?
First, in the case of NADPH, it is the key for determining the efficiency of certain biosynthetic pathways. The oxidation during a pentose phosphorylation produces most NADPH which is needed in the biosynthesis of certain metabolites. Therefore, the carbon flow of the pentose phosphorylation path is considered to be the targets of metabolic engineering. To summarize, if we find a path with improved NADPH yield, we could get more products in other relevant paths.

We used the Web so that the users, including ordinary people, can easily access to our software. After connecting to the program simply via a web browser, one can obtain the desired biological path by entering the starting compound and the terminal compound. To show the information of the path that has been processed with TSV, JSON form via accessible Web, we used D3.JS so that Javascript library can support various graphs.
Our program recognizes the biological paths as a "network", and visualizes the paths by representing the compounds as nodes and the chemical reaction as the edges connecting the nodes. When a user inputs a starting compound and a terminal compound of the desired path, the program will show the possible routes. The selected pathways that has been chosen by the team through four criteria, can be confirmed by pressing a button. The user may check whether the pathway, or the specific biological reaction, is included in the metabolic pathways of E. coli. It also provides the information such as coenzyme (ATP, NADH), CO2, G, to determine whether it can be applied to actual experiments or not. A bar graph and a line graph are provided to confirm whether there is a difference between each pathway, and to identify how it changes as the reaction progresses. Furthermore, one can download the information of the pathway we calculated and the gene data of the enzymes which is needed in the chemical reaction
Alberts, B., A. Johnson, J. Lewis, and et al. Molecular Biology of the Cell. 4th edition. New York: Garland Science, 2002.
BogoradI. W., LinT. S., LiaoJ. C. “Synthetic non-oxidative glycolysis enables complete carbon conservation.” “Nature”, 2013: 693-697.
FlamholzA., NoorE., Bar-EvenA., MiloR. “eQuilibrator—the biochemical thermodynamics calculator.” “Nucleic Acids Res.”, 2012: D770-D775.
KanehisaM., GotoS. “KEGG: Kyoto Encyclopedia of Genes and Genomes.” “Nucleic Acids Res”, 2000: 27-30.
KanehisaM., GotoS., SatoY., KawashimaM., FurumichiM., TanabeM. “Data, information, knowledge and principle: back to metabolism in KEGG.” “Nucleic Acids Res”, 2014: D199-D205.